中国bilibili、1枚の画像からアニメを生成するAIを発表 資料に日本アニメの画像を堂々と掲載
中国の大手動画共有サービス・bilibili(ビリビリ)の研究チームが、静止画からアニメ動画を生成するAI「AniSora」を発表した。
同ツールはワンクリックで静止画から動画生成が可能となるもので、無償公開されている。HuggingFaceやGitHubでモデルなどをダウンロードできるほか、エンドユーザに向けてはプロジェクトのAIプラットフォーム「Komiko」でも提供される。
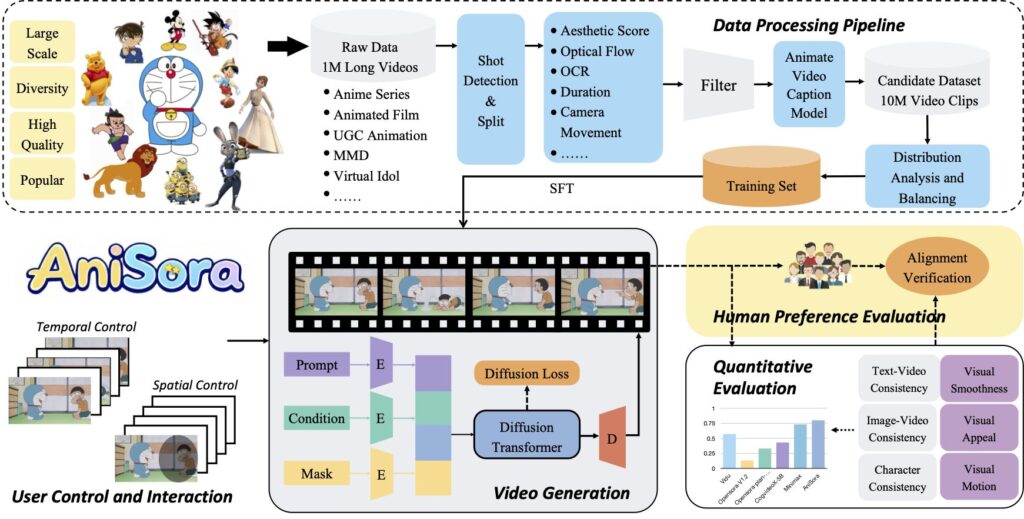
画像やテキストから動画を生成する研究はOpenAI社の「Sora」を筆頭に多数登場しているが、bilibiliチームによれば、これら従来の動画生成モデルは「アニメーション特有の誇張された動きや物理法則を無視した表現に対応できていない」との課題があると紹介。AniSoraはこの問題に対し、1000万を超える高品質データサンプルを用いたレーニングを実施することで、制御可能な生成モデルを導入することで対応していると紹介している。
トレーニングには商業アニメ映像に加え、ユーザー自主制作アニメや映画、3DCGモデル(MMD)など多くのデータを使用。公開されているサンプルでは、走るキャラクターの静止画かをもとに、手足を振って走る動画を生成する様子や、マンガのコマを元に口の動きや体の動きを追加したアニメコミックの制作を行う様子が確認できる。
ただし、公開されているサンプルには多くの商業アニメ作品が使われているようで、スタジオジブリ作品をはじめ「ドラえもん」「ライオンキング」といった人気アニメのシーンがデモサイトや研究資料の中に堂々と用いられている。真偽は不明だが、各社からの公表がないことからも、多くのトレーニング元となったデータは許可なく使用しているとみられる。


 購読
購読 配信
配信 RSS
RSS